索引是为了提高数据库查询效率而设计的,通过索引,数据库可以快速定位到需要的数据,避免全表扫描。我们可以很快想到一些可以提升查询效率的数据结构,如:哈希表(利用哈希算法,根据键快速找到值,一般用于等值查询)、有序数组(利用二分查找快速找到数据)、搜索树等。而我们常用的存储引擎 InnoDB 中,索引底层用到的数据结构是 B+树,B+树是一种平衡树,它的叶子节点存储实际的数据,而中间节点存储索引信息。通过这种结构,可以迅速定位到需要的数据。MySQL 中的表通常是按主键排序存储的,这样的表叫做“聚簇索引”表。每个索引都有一棵 B+树,表中每一行数据在不同的索引中都会有一条记录。这样,查询时,我们可以通过索引快速找到数据,而不必扫描整个表。
示例分析
以下面一张表为例:
1 | create table T( |
假设表中有数据:
| id | k | name |
|---|---|---|
| 1 | 100 | Jane |
| 2 | 200 | Mike |
| 3 | 300 | Nike |
| 4 | 400 | Jane |
| 5 | 500 | Phony |
每行的数据分别用:R1, R2, R3, R4, R5 所表示,上面的表会以 id 和 k 两个为索引分别创建两个索引树,类似下图所示: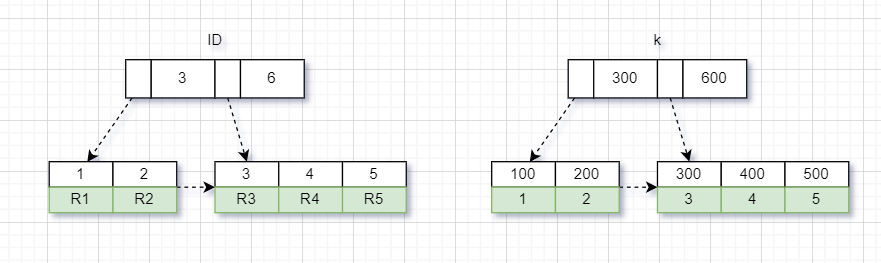
这时,数据库会为 id 和 k 创建两颗 B+树,像这样:
- 主键索引:id 作为主键排序,数据存储在 B+ 树的叶子节点中。
- 非主键索引:k 字段为非主键索引,B+树的叶子节点存储的是 k 的值和相应的主键 id。
主键索引 vs 非主键索引
主键索引(聚簇索引):查询主键时,B+树的叶子节点直接存储整行数据。例如,查询 select * from T where id = 2,只需查主键索引树。
非主键索引(二级索引):查询其他字段时,首先查找非主键索引,找到相应的主键值,再根据主键查询主键索引树;这种查询过程叫做回表。例如,查询 select * from T where k = 100:
首先会查 k 的索引,找到 k = 100 对应的 id = 1;然后根据 id = 1 去主键索引树中查找对应的整行数据。
覆盖索引
有时候,非主键索引不仅能帮助定位数据,还能直接返回查询结果,这种情况叫做覆盖索引。当查询的字段都能在某个索引的叶子节点中找到时,就不需要回表。例如,查询 “select id from T where k between 300 and 500”:这个查询只需要 id 字段,而 id 的值已经在 k 索引树的叶子节点中;所以,数据库可以直接通过 k 索引来返回查询结果,不需要回表查主键索引。使用覆盖索引可以显著减少查询开销,提高查询性能,因此它是数据库性能优化的常用手段。